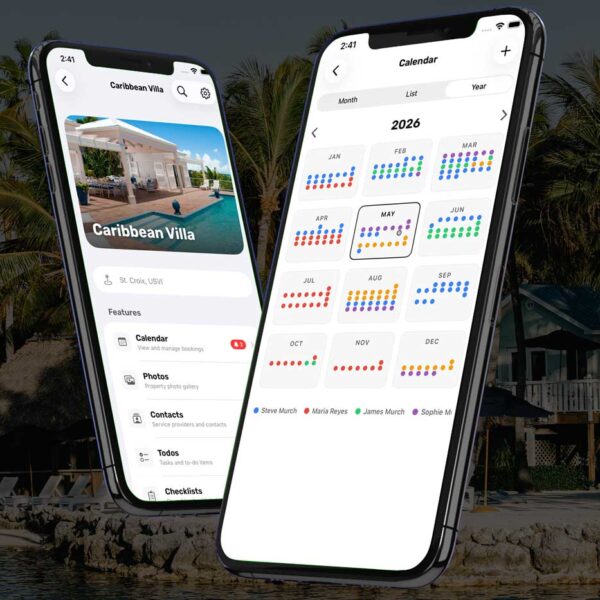
Post Grid #7Politics and NewsThe Ferry Is Free Steve Murch Jul 30, 2026The year is 1980. Windward and Leeward residents know the other island is full of bad people. Shared Vacation Home Calendar App on iPhone May 28, 2026Building a Water Tank Monitor for an Off-Grid Wellhouse May 23, 2026Washington State Income Tax: New Voters Guide Uses AI to Read the Tea Leaves on Judicial Candidates May 21, 2026